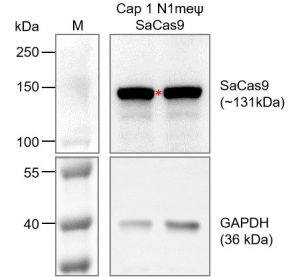
Cap 1 N1meψ SaCas9 mRNA
SaCas9 is a variant of the CRISPR-associated protein Cas9, originating from the bacterium Staphylococcus aureus. Like the more commonly used SpCas9 (derived from Streptococcus pyogenes), SaCas9 is an RNA-guided endonuclease enzyme that is utilized in genome editing applications. However, SaCas9 is smaller in size compared to SpCas9, making it advantageous for certain applications where size constraints are a consideration. Despite its smaller size, SaCas9 retains the ability to target specific DNA sequences and induce double-strand breaks, enabling precise genetic modifications. This mRNA possesses a Cap1 structure, which is highly efficient in capping. It is fully substituted with N1-methyl-pseudo Uridine to improve expression and decrease immunogenicity. Additionally, the mRNA features a 110A tail in its sequence, resembling a mature mRNA.